

Tornando all' evoluzione deterministica per i prossimi giorni io aspetterei il cambio di pattern nel pacifico PNA perché ancora quest' anno nn ha passato la soglia negativa ..mi aspetto nei prossimi run una maggiore presa dinamica dell' onda atlantica a discapito del collegamento , che ora fanno vedere i GM , tra lobo euroasiatico e canadese .. attendiamo anche la lettura dei valori delle temperature al suolo e l' opposizione termica .. oggi è il 13 ..penso che tra il 15 e il 16 le visioni per la terza decade cambieranno nei modelli ..
pensi che in modelli non abbiano gia implementato i dati di cambio fase del pna....??!Originariamente Scritto da Bortan


Beato colui che nulla si aspettava....... perché non rimarra' deluso!(Il maggiore John Urgayle )
Grazie per le precisazioni.
Ti chiedo, se possibile, un riferimento ad un articolo che tratti di questo argomento.
Buongiorno, volevo porre una domanda ai più esperti: al di là di tutte le vicende stratosferiche, quanta importanza date alle enormi anomalie positive in area RM in merito alla modulazione del getto in uscita dagli States
Inoltre gli effetti di Nina ed eventualmente PNA/PDO- potranno modificare questo assetto secondo me molto penalizzante in Atlantico?
Inviato dal mio POCOPHONE F1 utilizzando Tapatalk
ottima domanda
direi che guardando a distanza di un mese è palese come finalmente il nord del pacifico stia progressivamente riassettando i poli di anomalia e come questo andrà a riscrivere la dinamica del treno d'onda anche sull'altro oceano
ugualmente questo riassetto medio per l'uscita in atl andrà a incidere sulla capacità dell'amoc di andare a impattare l'hc in zona nao
C'ho la falla nel cervello
Qui c'è tanta roba: IFS documentation | ECMWF
In ogni caso il "mito" della statistica nelle corse deterministiche deriva dalla parametrizzazione. Come detto la non linearità delle equazioni differenziali, la risoluzione dei modelli (non si può certo pensare di modellare ogni singolo nucleo di condensazione, cristallo di neve, goccia di pioggia etc...) implica delle semplificazioni più o meno brutali. Il nome che si da a queste semplificazioni è "parametrizzazione".
Ossia l'uomo decide i parametri per spostare "un pò più in qua, un pò più in là" il comportamento dei modelli.
Chiaramente in questi parametri c'è una sorta di statistica, cioè si prova a migliorare in base agli score del modello nella versione precedente.
Ma una statistica vera e propria non esiste, l’output è il risultato deterministico delle equazioni differenziali senza null'altro.
sempre preziosi i tuoi contributi Angelo
C'ho la falla nel cervello
E io ne approfitto per un'altra domanda allora.
Qualche anno fa fu detto che ecmwf teneva conto in qualche modo della sua corsa precedente?
Ne sai qualcosa?
Penso ancora che sia presto ...qualcosa si vede in gem e ecmwf sulle 200 h +o- .. è una dinamica in divenire ...quindi aspetterei 2 o 3 giorni almeno per verificare l' impatto sul wave train in atlantico ..

Ciao Gio,
allora banalmente la corrente a getto rappresenta il profilo altimetrico più elevato in troposfera in termini di pressione/temperatura fra due fasce limitrofe, una più fredda a nord e una più calda a sud (salvo eccezioni: inversione di gradiente).
Questa si trova a quote variabili e normalmente contenuta in una fascia di pressione che va dai 200 ai 300 hpa.
La condotta della corrente a getto influenza gli indici descrittivi (NAO/AO/PNA) ed è influenzata da forzanti rappresentati da indici climatici quali ad esempio Enso/Mjo/Qbo quindi media frequenza e da altri a bassa frequenza quali AMO/PDO.
Il comportamento della corrente a getto quindi è soggetta a fattori che ne possono variare anche improvvisamente la condotta (come un ESE) all'interno di un trend che a sua volta segue un percorso tracciato da indici a bassa frequenza.
Non esiste pertanto un solo parametro ma, tra gli indici costitutivi (o forzanti), una somma di fattori che possono sommariamente pronosticarne l'andamento o stagionale (quindi con un focus di breve periodo) o il trend all'interno di un periodo più lungo (10/20 anni).
Non so se ti ho risposto al tuo quesito
Ultima modifica di mat69; 13/01/2021 alle 14:49
Matteo
 Permessi di Scrittura
Permessi di Scrittura


 Rispondi Citando
Rispondi Citando
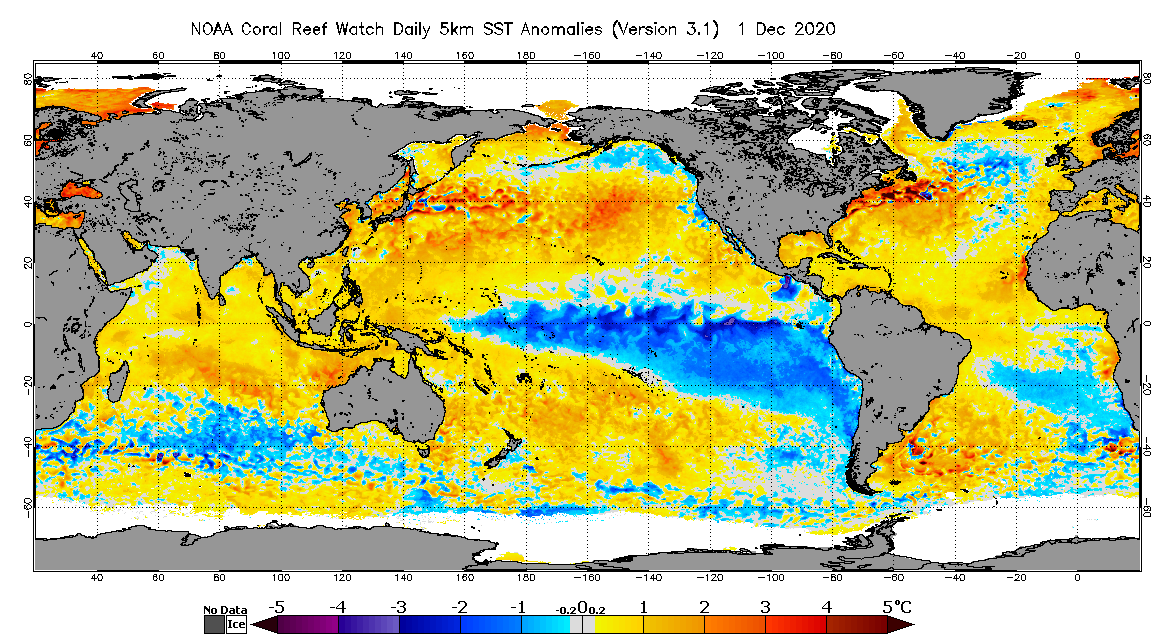
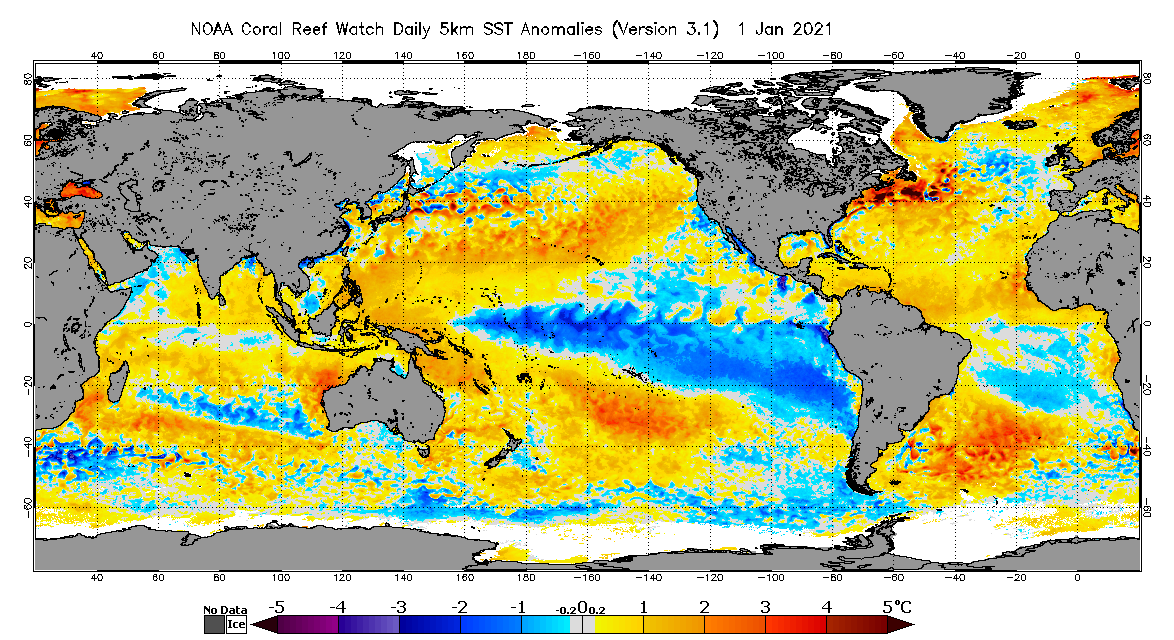
 ) oltre ad essere influenzato da fattori "esogeni" al sistema (come può essere, ad esempio, T-S-T di tipo "cold" che può portare successivamente ad un accorpamento delle masse artiche e quindi ad un rinforzo del getto nel nord atlantico).
) oltre ad essere influenzato da fattori "esogeni" al sistema (come può essere, ad esempio, T-S-T di tipo "cold" che può portare successivamente ad un accorpamento delle masse artiche e quindi ad un rinforzo del getto nel nord atlantico).




Segnalibri